Questions to ask AI first when reading unfamiliar legacy code
Unfamiliar legacy code feels heavy for a reason. The problem is not just old style or missing comments. The real problem is that everything looks potentially important at the same time.
That is where developers misuse AI. They paste a large file and ask, “What does this do?” The answer is often too broad, too smooth, and too expensive to trust.
A better starting point is not a bigger explanation. It is a smaller question set. AI becomes more useful when it helps you decide what to inspect first.
1. Do not ask for a full explanation first
A full explanation usually compresses too much. It gives you a story about the file before you know which parts actually matter for the bug, feature, or change you are holding.
That creates false comfort. The summary sounds coherent, but you still do not know where execution starts, what hidden side effects exist, or which external system the module depends on.
2. The best first questions shrink the reading surface
This is the core shift. When reading legacy code, the fastest progress usually comes from shrinking the surface area, not from increasing explanation volume.
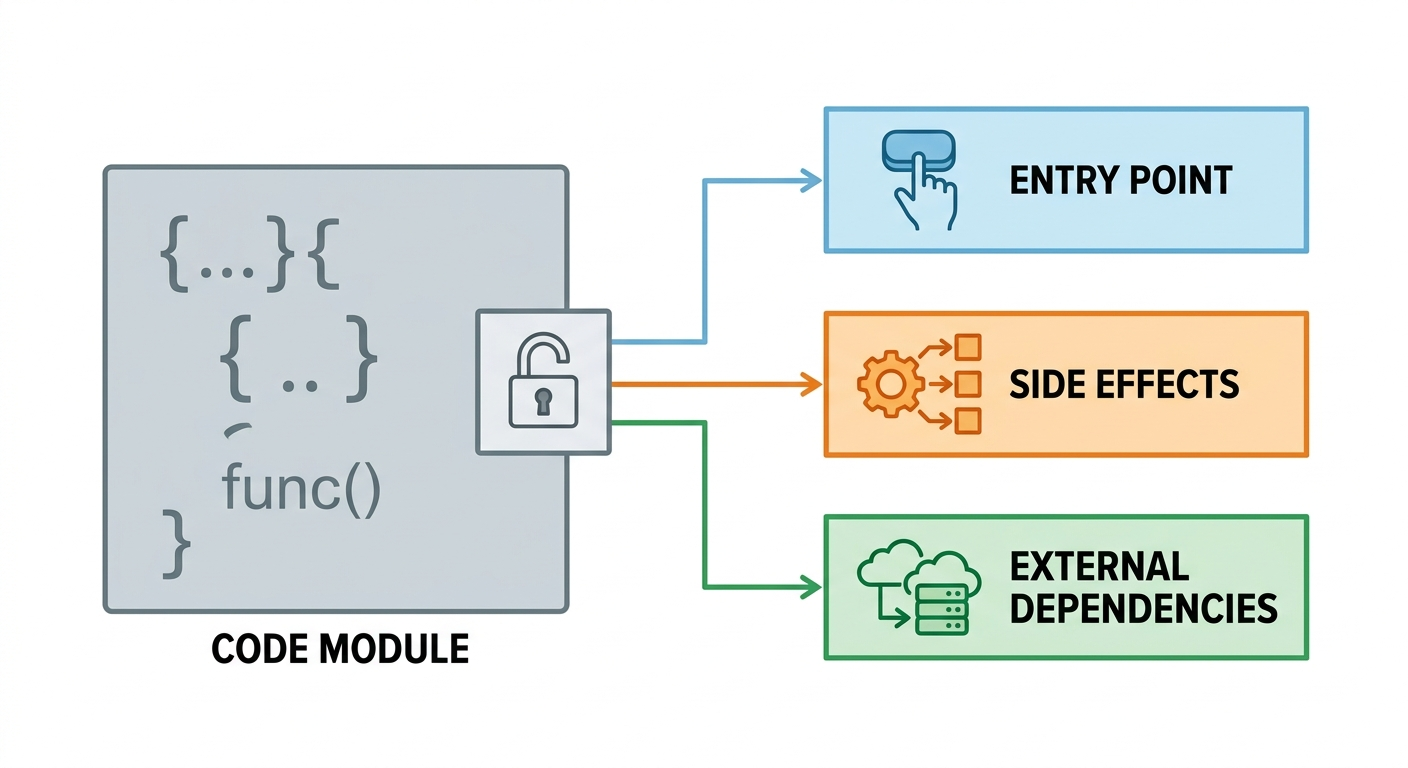
Three questions do most of the early work:
- Where is the entry point?
- What side effects does this code cause?
- Which external dependencies or data boundaries does it touch?
Those questions matter because they turn one heavy file into one execution map. Entry point tells you where to start. Side effects tell you what changes after the code runs. External dependencies tell you where hidden behavior may enter from outside the file.
Without those three, teams often read legacy code line by line and still miss the real shape of it. They know what individual functions look like, but not which part of the file is structurally important.
AI is useful here because it can quickly outline these boundaries if you ask for them directly. “Show me the entry path and side effects” is far more actionable than “Explain this code.”
3. Ask AI for map questions, not prose questions
Good prompts here are map-like:
Given this file, show the likely entry point, any side effects, and the external dependencies it touches. Keep the answer short and structured.
You can add one more prompt when the file is especially noisy:
Which functions are safe to ignore on a first read, and which ones should I inspect first if I need to change behavior?
4. One practical example changes the reading order
Imagine a large service file that handles request validation, caching, database writes, and analytics dispatch in one place. If you read it top to bottom, everything looks equally important.
If you ask for entry point, side effects, and dependencies first, the file becomes easier to triage. You may learn that only one exported function matters, two helper functions are pure, and the real risk sits at the cache write and analytics dispatch boundary.
That changes the reading order immediately. You stop reading for completeness and start reading for leverage.
5. Keep one short code-reading template
You do not need a complex workflow. A small template is enough:
- entry point
- side effects
- external dependencies
- safe-to-ignore parts
- risky change points
The better the template, the less AI has room to invent a confident but useless overview.
What to do first
Take one unfamiliar file from your current work and ask AI for only the entry point, side effects, and external dependencies. If the file still feels equally wide after that, the question was not narrow enough.